
Experiments in Tracking Canons across the Mecelle
Posted on April 01, 2022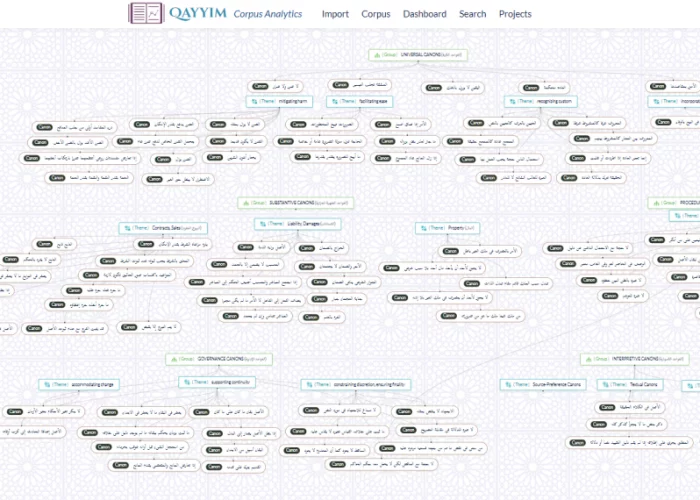
Last term, we convened a CnC Research Working Group to bring together a global group of scholars interested in interpretation in Islamic law to share works in progress, read texts, and discuss new ideas on research questions relevant to the history of interpretation, courts, and canons. One aim was to better understand legal canons as tools for interpretation in historical context. A second aim was to see whether and how data science tools can augment that process. To those ends, we meet to workshop works-in-progress deliberately designed to be ‘half-baked ideas’ at the preliminary stages of research. We experiment with ways in which data science tools of the type we are developing at SHARIAsource (CnC Qayyim) can aid in that research.
Case in point: our most recent workshop on the Ottoman Code of 1869, better known as the Mecelle. Professor Intisar Rabb and PIL Data Science Fellow, Dr. Yusuf Celik, explored debates over how and why the Mecelle Drafting Committee borrowed 99 legal canons to reform Ottoman law. They and the Research Group raised several questions: By looking at patterns of canons clusters that the CnC tools helped produce, what conclusions can we form about why the Mecelle scholars made certain choices over others for which canons to include in their short list of 99 legal canons? If tracking canons across texts, how extensive would a corpus need to be to definitively answer the questions posed? What types of sources would add greater insight into applications of those canons in late-Ottoman law and society? Together, we worked through the clustering of canons in the ‘Mecelle Flow,’ highlighted in the image above. The authors will go back to the digital drawing board to further develop the tools and prepare a paper to publish the results. Read more here!